Using nbconvert as a Library¶
In this Notebook, you will be introduced to the programatic API of nbconvert and how it can be used in various contexts.
One of @jakevdp's great blog posts will be used to demonstrate. This notebook will not focus on using the command line tool. The attentive reader will point-out that no data is read from or written to disk during the conversion process. Nbconvert has been designed to work in memory so that it works well in a database or web-based environement too.
Quick overview¶
Credit, Jonathan Frederic (@jdfreder on github)
<center>
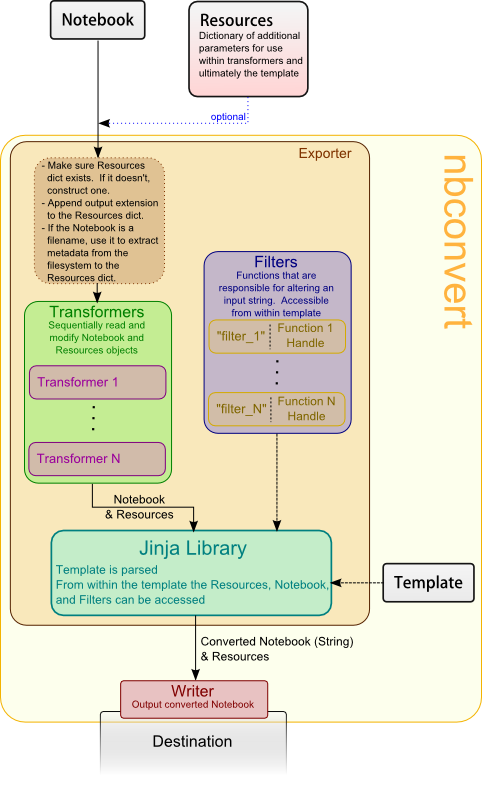 </center>
</center>
The main principle of nbconvert is to instantiate an Exporter that controls
the pipeline through which notebooks are converted.
First, download @jakevdp's notebook.
import requests
response = requests.get('http://jakevdp.github.com/downloads/notebooks/XKCD_plots.ipynb')
response.text[0:60]+'...'
If you do not have requests, install it by running pip install requests (or if you don't have pip installed, you can find it on PYPI).
The response is a JSON string which represents an IPython notebook. Next, read the response using nbformat.
Doing this will guarantee that the notebook structure is valid. Note that the in-memory format and on disk format are slightly different. In particual, on disk, multiline strings might be splitted into a list of strings.
from IPython import nbformat
jake_notebook = nbformat.reads(response.text, as_version=4)
jake_notebook.cells[0]
The nbformat API returns a special dict. You don't need to worry about the details of the structure.
The nbconvert API exposes some basic exporters for common formats and defaults. You will start by using one of them. First you will import it, then instantiate it using most of the defaults, and finally you will process notebook downloaded early.
from traitlets.config import Config
from IPython.nbconvert import HTMLExporter
# The `basic` template is used here.
# Later you'll learn how to configure the exporter.
html_exporter = HTMLExporter(config=Config({'HTMLExporter':{'default_template':'basic'}}))
(body, resources) = html_exporter.from_notebook_node(jake_notebook)
The exporter returns a tuple containing the body of the converted notebook, raw HTML in this case, as well as a resources dict. The resource dict contains (among many things) the extracted PNG, JPG [...etc] from the notebook when applicable. The basic HTML exporter leaves the figures as embeded base64, but you can configure it to extract the figures. So for now, the resource dict should be mostly empty, except for a key containing CSS and a few others whose content will be obvious.
Exporters are stateless, so you won't be able to extract any usefull information beyond their configuration from them. You can re-use an exporter instance to convert another notebook. Each exporter exposes, for convenience, a from_file and from_filename method.
print([key for key in resources ])
print(resources['metadata'])
print(resources['output_extension'])
# print resources['inlining'] # Too long to be shown
# Part of the body, here the first Heading
start = body.index('<h1 id', )
print(body[:400]+'...')
If you understand HTML, you'll notice that some common tags are ommited, like the body tag. Those tags are included in the default HtmlExporter, which is what would have been constructed if no Config object was passed into it.
Extracting Figures¶
When exporting you may want to extract the base64 encoded figures as files, this is by default what the RstExporter does (as seen below).
from IPython.nbconvert import RSTExporter
rst_exporter = RSTExporter()
(body,resources) = rst_exporter.from_notebook_node(jake_notebook)
print(body[:970]+'...')
print('[.....]')
print(body[800:1200]+'...')
Notice that base64 images are not embeded, but instead there are file name like strings. The strings actually are (configurable) keys that map to the binary data in the resources dict.
Note, if you write an RST Plugin, you are responsible for writing all the files to the disk (or uploading, etc...) in the right location. Of course, the naming scheme is configurable.
As an exercise, this notebook will show you how to get one of those images.
list(resources['outputs'])
There are 5 extracted binary figures, all pngs, but they could have been svgs which then wouldn't appear in the binary sub dict. Keep in mind that objects with multiple reprs will have every repr stored in the notebook avaliable for conversion.
Hence if the object provides _repr_javascript_, _repr_latex_, and _repr_png_, you will be able to determine, at conversion time, which representaition is most appropriate. You could even show all of the representaitions of an object in a single export, it's up to you. Doing so would require a little more involvement on your part and a custom Jinja template.
Back to the task of extracting an image, the Image display object can be used to display one of the images (as seen below).
from IPython.display import Image
Image(data=resources['outputs']['output_3_0.png'],format='png')
This image is being rendered without reading or writing to the disk.
Extracting figures with HTML Exporter ?¶
Use case:
> I write an awesome blog using IPython notebooks converted to HTML, and I want the images to be cached. Having one html file with all of the images base64 encoded inside it is nice when sharing with a coworker, but for a website, not so much. I need an HTML exporter, and I want it to extract the figures!
Some theory¶
The process of converting a notebook to a another format with happens in a few steps:
- Retrieve the notebook and it's accompanying resource (you are responsible for this).
- Feed them into the exporter, which:
- Sequentially feeds them into an array of
Preprocessors. Preprocessors only act on the structure of the notebook, and have unrestricted access to it. - Feeds the notebook into the Jinja templating engine.
- The template is configured (you can change which one is used).
- Templates make use of configurable macros called
filters.
- Sequentially feeds them into an array of
- The exporter returns the converted notebook and other relevant resources as a tuple.
- You write the data to the disk, or elsewhere (you are responsible for this too).
You can use Preprocessors to accomplish the task at hand. IPython has preprocessors built in which you can use. One of them, the ExtractOutputPreprocessor is responsible for crawling the notebook, finding all of the figures, and putting them into the resources directory, as well as choosing the key (i.e. filename_xx_y.extension) that can replace the figure inside the template.
The ExtractOutputPreprocessor is special because it's available in all of the Exporters, and is just disabled in some by default.
# 3rd one should be <ExtractOutputPreprocessor>
html_exporter._preprocessors
Use the IPython configuration/Traitlets system to enable it. If you have already set IPython configuration options, this system is familiar to you. Configuration options will always of the form:
ClassName.attribute_name = value
You can create a configuration object a couple of different ways. Everytime you launch IPython, configuration objects are created from reading config files in your profile directory. Instead of writing a config file, you can also do it programatically using a dictionary. The following creates a config object, that enables the figure extracter, and passes it to an HTMLExporter. The output is compared to an HTMLExporter without the config object.
from traitlets.config import Config
c = Config({
'ExtractOutputPreprocessor':{'enabled':True}
})
exportHTML = HTMLExporter()
exportHTML_and_figs = HTMLExporter(config=c)
(_, resources) = exportHTML.from_notebook_node(jake_notebook)
(_, resources_with_fig) = exportHTML_and_figs.from_notebook_node(jake_notebook)
print('resources without the "figures" key:')
print(list(resources))
print('')
print('ditto, notice that there\'s one more field:')
print(list(resources_with_fig))
list(resources_with_fig['outputs'])
Custom Preprocessor¶
There are an endless number of transformations that you may want to apply to a notebook. This is why we provide a way to register your own preprocessors that will be applied to the notebook after the default ones.
To do so, you'll have to pass an ordered list of Preprocessors to the Exporter's constructor.
For simple cell-by-cell transformations, Preprocessor can be created using a decorator. For more complex operations, you need to subclass Preprocessor and define a call method (as seen below).
All transforers have a flag that allows you to enable and disable them via a configuration object.
from IPython.nbconvert.preprocessors import Preprocessor
import traitlets.config
print("Four relevant docstring")
print('=============================')
print(Preprocessor.__doc__)
print('=============================')
print(Preprocessor.preprocess.__doc__)
print('=============================')
print(Preprocessor.preprocess_cell.__doc__)
print('=============================')
Example¶
The following demonstration was requested in an IPython GitHub issue, the ability to exclude a cell by index.
Inject cells is similar, and won't be covered here. If you want to inject static content at the beginning/end of a notebook, use a custom template.
from traitlets import Integer
class PelicanSubCell(Preprocessor):
"""A Pelican specific preprocessor to remove some of the cells of a notebook"""
# I could also read the cells from nbc.metadata.pelican is someone wrote a JS extension
# But I'll stay with configurable value.
start = Integer(0, config=True, help="first cell of notebook to be converted")
end = Integer(-1, config=True, help="last cell of notebook to be converted")
def preprocess(self, nb, resources):
#nbc = deepcopy(nb)
nbc = nb
# don't print in real preprocessor !!!
print("I'll keep only cells from ", self.start, "to ", self.end, "\n\n")
nbc.cells = nb.cells[self.start:self.end]
return nbc, resources
# I create this on the fly, but this could be loaded from a DB, and config object support merging...
c = Config()
c.PelicanSubCell.enabled = True
c.PelicanSubCell.start = 4
c.PelicanSubCell.end = 6
Here a Pelican exporter is created that takes PelicanSubCell preprocessors and a config object as parameters. This may seem redundant, but with the configuration system you can register an inactive preprocessor on all of the exporters and activate it from config files or the command line.
pelican = RSTExporter(preprocessors=[PelicanSubCell], config=c)
print(pelican.from_notebook_node(jake_notebook)[0])
Programatically make templates¶
from jinja2 import DictLoader
dl = DictLoader({'full.tpl':
"""
{%- extends 'basic.tpl' -%}
{% block footer %}
FOOOOOOOOTEEEEER
{% endblock footer %}
"""})
exportHTML = HTMLExporter(extra_loaders=[dl])
(body,resources) = exportHTML.from_notebook_node(jake_notebook)
for l in body.split('\n')[-4:]:
print(l)
Real World Use¶
@jakevdp uses Pelican and IPython Notebook to blog. Pelican will use nbconvert programatically to generate blog post. Have a look a Pythonic Preambulations for Jake's blog post.
@damianavila wrote the Nicholas Plugin to write blog post as Notebooks and is developping a js-extension to publish notebooks via one click from the web app.
<center>
</center>As @Mbussonn requested... easieeeeer! Deploy your Nikola site with just a click in the IPython notebook! http://t.co/860sJunZvj cc @ralsina
— Damián Avila (@damian_avila) August 21, 2013
A few gotchas¶
Jinja blocks use {% %}by default which does not play nicely with $\LaTeX$, hence thoses are replaced by ((* *)) in latex templates.